Text Clustering With Deepseek Reasoning
We will develop and understand a novel approach to text clustering and explain our inference results using the DeepSeek reasoning model.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we will explore the world of reasoning in LLM. DeepSeek has provided us with an excellent tool to explain our inferences and build machine learning systems that inspire more confidence and trust from end users.
Machine learning models are black boxes by default and do not provide out-of-box explanations (XAI) for their decisions. We will use the DeepSeek model and try to add the explanation or reasoning aspect to our machine learning world.
Methodology
We will build custom embeddings and an embedding function to create a vector datastore and use the DeepSeek model to perform reasoning.
Here is a simple flowchart demonstrating the overall process flow.
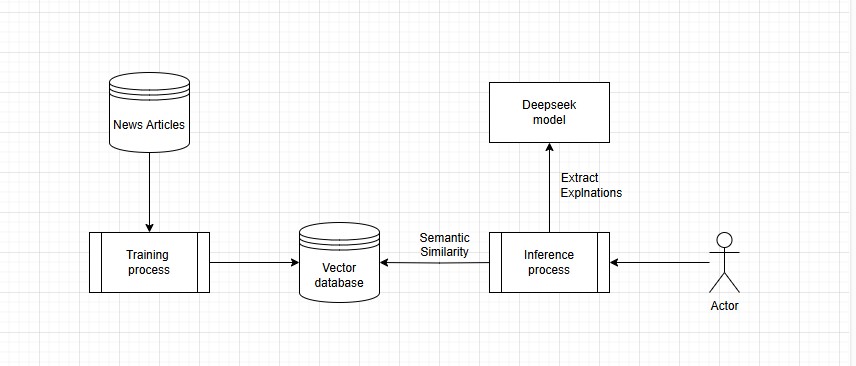
Data
1. We will select a news article dataset to identify the category of new article. The dataset is available on the Kaggle website to download.
2. From the dataset, we will use short_description for vector embedding and the category feature to assign appropriate tags to each article.
3. The dataset is fairly clean, and no preprocessing is required to be performed on it.
4. We will use the pandas library to load the dataset and scikit-learn to split it into training and test datasets.
import pandas as pd
df = pd.read_json('./News_Category_Dataset_v3.json',lines=True)
from sklearn.model_selection import train_test_split
# Separate features (X) and target (y)
X = df.drop('category', axis=1)
y = df['category']
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
train_df = pd.concat([X_train, y_train], axis=1)
test_df = pd.concat([X_test, y_test], axis=1)Generate Text Embeddings
1. We will use the following libraries for our text embeddings:
langchain– For creating example prompts and semantic similarity selectorslangchain_chroma– For creating embeddings and storing them in a datastore
from chromadb import Documents, EmbeddingFunction, Embeddings
from langchain_chroma import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate2. Next, we will build the custom embedding and embedding functions. These custom functions will allow us to query a model deployed locally or on a remote instance.
Readers can incorporate the necessary security mechanisms (HTTPS, Data encryption, etc.) for an instance deployed at a remote instance and invoke a REST endpoint to retrieve model embeddings.
class MyEmbeddings(Embeddings):
def __init__(self):
# Server address and port (replace with your actual values)
self.url = ""
# Request headers
self.headers = {
"Content-Type": "application/json"
}
self.data = {
# Use any text embedding model of your choice
"model": "text-embedding-nomic-embed-text-v1.5",
"input": None,
"encoding_format": "float"
}
def embed_documents(self, texts):
embeddings = []
for text in texts:
embeddings.append(self.embed_query(text))
return embeddings
def embed_query(self, input):
self.data['input'] = input
with requests.post(self.url, headers=self.headers, data=json.dumps(self.data)) as response:
res = response.text
yaml_object = yaml.safe_load(res)
embeddings = yaml_object['data'][0]['embedding']
return embeddings
class MyEmbeddingFunction(EmbeddingFunction):
def __call__(self, input: Documents) -> Embeddings:
return MyEmbeddings()3. We will define a simple function that will create a semantic similarity selector for the news article. The selector will be used to create vector embeddings using the training dataset.
def create_semantic_similarity_selector(train_df):
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
# Examples of a pretend task of creating antonyms.
examples = []
for row in train_df.iterrows():
example = {}
example['input'] = row[1]['short_description']
example['output'] = row[1]['category']
examples.append(example)
semantic_similarity_selector = SemanticSimilarityExampleSelector.from_examples(
# The list of examples available to select from.
examples,
# The embedding class used to produce embeddings which are used to measure semantic similarity.
MyEmbeddings(),
# The VectorStore class that is used to store the embeddings and do a similarity search over.
Chroma,
# The number of examples to produce.
k=1,
)
return semantic_similarity_selector4. We invoke the above function to generate the embeddings for news articles. Please note that the training process can be time-consuming, and we can parallelize it to make it faster.
semantic_similarity_selector = create_semantic_similarity_selector(train_df)5. The chroma vector datastore stores the vector representations of the various news articles and their associated labels. We will use the embeddings in the datastore to perform semantic similarity with the articles in the test dataset, and check the accuracy of the approach.
6. We will invoke the DeepSeek REST endpoint and pass the response received from the semantic similarity selector and the actual result to the test dataset. We will then create a context that contains the required information for the DeepSeek model to perform reasoning.
def explain_model_result(text, model_answer, actual_answer):
# REST end point for deepseek model.
url = ""
# Request headers
headers = {
"Content-Type": "application/json"
}
promptJson = {
"question": 'Using the text, can you explain why the model answer and actual answer match or do not match ?',
"model_answer": model_answer,
"actual_answer": actual_answer,
"context": text,
}
prompt = json.dumps(promptJson)
# Request data (replace with your prompt)
data = {
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.7,
"stream": True
}
captured_explanation = ""
with requests.post(url, headers=headers, data=json.dumps(data), stream=True) as response:
if response.status_code == 200:
for chunk in response.iter_content(chunk_size=None):
if chunk:
# Attempt to decode the chunk as UTF-8
decoded_chunk = chunk.decode('utf-8')
# Process the chunk as a json or yaml to extract the explanation and concat it with captured_explanation object.
captured_explanation += yaml.safe_load(decoded_chunk)['data']['choices'][0]['delta']['content']
else:
print(f"Request failed with status code {response.status_code}")
return captured_explanationBelow, we parse our test dataset and capture the explanation from the DeepSeek model.
results_df = pd.DataFrame()
results_df['input'] = None
results_df['model_answer'] = None
results_df['actual_answer'] = None
results_df['explanation'] = None
for row in test_df.iterrows():
example = {}
example['input'] = row[1]['short_description']
model_result_category = semantic_similarity_selector.select_examples(example)
example['explanation'] = explain_model_result(example['input'],model_result_category[0]['output'],row[1]['category'])
example['model_answer'] = model_result_category[0]['output']
example['input'] = row[1]['category']
results_df.loc[len(results_df)] = exampleResults
We will share the results for some of the scenarios in our test dataset.
1. The first example is when there is a mismatch between the answer captured from semantic similarity and the actual answer in the test dataset. The insight provides us with an understanding of whether the model is reasonable in making the predictions. The think tags provide us with the initial thought process of the DeepSeek model to understand the problem statement, and then it collates the answer for the end user.
In the first example, DeepSeek can explain why the model got the incorrect answer. The model only considers the travel aspect of the sentence and not the entertainment aspect. This means that our embedding model would need more entertainment examples to train.
<think>
Okay, so I'm trying to figure out why the model answer is "TRAVEL" and the actual answer is "ENTERTAINMENT." The context given is about going to Central Park and the Delacorte Theater to see Shakespeare under the night sky, with rain expected.
First, I need to understand what each term refers to. TRAVEL relates to visiting places, moving around, or tourism in general. ENTERTAINMENT is more about enjoyable activities, like theater, concerts, movies, etc., that provide pleasure.
Looking at the context: the person went to Central Park, which is a place they traveled to. Then they went to the Delacorte Theater for a Shakespeare performance. So, the main activities are both TRAVEL and ENTERTAINMENT because they're going out, seeing a play.
But why would there be a mismatch between model and actual answers? Maybe the model didn't consider that travel can also include attending theater or other performances as part of the entertainment aspect. So the actual answer is broader, including both aspects, while the model focuses only on TRAVEL.
Alternatively, perhaps the context doesn't emphasize one over the other. The key points are moving to a place (TRAVEL) and attending an event for enjoyment (ENTERTAINMENT). Depending on the focus, either could be considered the main answer, but typically, when someone goes somewhere to attend an event, both travel and entertainment elements come into play.
So, the model answer might have only picked TRAVEL, not considering ENTERTAINMENT. The actual answer includes both aspects, hence the mismatch.
</think>
The discrepancy between the model answer "TRAVEL" and the actual answer "ENTERTAINMENT" arises from the context provided. While travel is indeed part of the narrative—visiting Central Park—the primary focus is on attending a theater performance, which falls under entertainment. The actual answer captures both elements: moving to a place (travel) and engaging in an enjoyable event (entertainment). Thus, the model may have overlooked the entertainment aspect, considering only travel, whereas the actual response encompasses both activities.
**Answer:**
The model answer "TRAVEL" focuses on visiting places, while the actual answer "ENTERTAINMENT" includes attending a theater performance. The context highlights both elements, leading to the mismatch in answers.2. We will consider the scenario in which the model's answer and the actual answer did not match. However, the model was reasonable in making the prediction.
In the second example, the armed robbery in FRANCE is a CRIME and hence the model tagging of the user article as CRIME is not necessarily incorrect. The reasoning from DeepSeek is able to provide decent justification of the result.
<think>
Okay, so I'm trying to figure out why the model answer is "CRIME" and the actual answer is "WORLD NEWS" given the context: "French police recovered the merchandise stolen in an armed robbery on Wednesday."
First, I need to understand what each part of this question is asking. The user wants me to explain why these two answers match or don't match based on the provided text. So, maybe I should start by analyzing the context and seeing how it relates to both CRIME and WORLD NEWS.
Looking at the context: It's about French police recovering stolen merchandise from an armed robbery. An armed robbery is definitely a crime, so that makes sense why "CRIME" is an answer. The model answer being CRIME aligns with the event described because it's a criminal act—a robbery.
Now, why is WORLD NEWS also an answer? Well, if I think about news in general, events like this are newsworthy. So perhaps the actual answer is considering that this incident is part of world news because it involves police action and theft, which can be significant enough to be reported internationally.
But wait, does the context specify whether it's considered world news or not? It just mentions French police recovering stolen goods in an armed robbery on Wednesday. Without more details about the scale or international implications, I'm not sure if it's explicitly world news. Maybe WORLD NEWS is a broader category that includes such events as part of their reporting.
So, why do they match and why don't they? They both are relevant because CRIME is directly related to the event, while WORLD NEWS is considering the newsworthiness of the event. But perhaps the model answer is more focused on the specific event being a crime, whereas WORLD NEWS is taking a broader view of news events.
I'm also thinking about how each answer approaches the context differently. The model answer is zeroing in on the type of event (crime), while the actual answer is considering it as a newsworthy event that might be reported in world news sections or channels.
So, to sum up, both answers are relevant but approach the context from different angles—Crime specifically relates to the event's nature, whereas WORLD NEWS broadens it into the realm of news reporting.
</think>
The model answer "CRIME" and the actual answer "WORLD NEWS" both address the provided context, but they do so from different perspectives.
**CRIME**: The context explicitly describes an armed robbery, which is a criminal act. Therefore, "CRIME" directly relates to the nature of the event.
**WORLD NEWS**: While the event is indeed newsworthy, the term "WORLD NEWS" broadens the scope beyond the specific details, considering it as part of international or general news reporting.
In essence, both answers are relevant but focus on different aspects: "CRIME" highlights the event's nature as a criminal act, while "WORLD NEWS" recognizes its potential newsworthiness.3. We will consider the reasoning when the model and the actual answers match.
The reasoning behind the matching results enhances our trust and builds our confidence in the model predictions.
<think>
Okay, so I'm trying to understand why the model answer and the actual answer both say "MEDIA" when explaining the context. The question is asking me to explain whether they match or not based on the given text.
First, let me look at the context provided: "The newsroom is awash with fears about the casino mogul's intentions after his refusal to admit ownership." This sentence mentions a casino mogul and their refusal to own up to something. That refusal is causing fear in the newsroom regarding their intentions.
Now, looking at both the model answer and the actual answer, they both are "MEDIA". I think this might be an abbreviation or shorthand for media-related reasons. The context talks about the newsroom, which is a place associated with media organizations or journalists. So, when there's fear about someone's intentions, especially related to ownership, it makes sense that the media would be concerned and involved.
Wait, but why specifically does it say "MEDIA"? Maybe it's short for something else or maybe it's just a coincidence. However, given that the context is in a newsroom setting, it's likely referring to media-related issues.
Let me break it down: The casino mogul refusing ownership could imply some kind of hidden agenda or control. Since this is in a newsroom, which deals with reporting and information, the refusal might be seen as trying to hide something. This fear could lead to media coverage or reporting on it, hence the mention of MEDIA.
So, putting it together, both answers refer to the involvement or concern of media outlets regarding the casino mogul's actions. Therefore, they match because the context clearly ties into a media-related situation.
</think>
The model answer and actual answer both state "MEDIA" because the context provided refers to a newsroom setting, where concerns about a casino mogul's intentions are likely related to media involvement or reporting. The refusal to admit ownership sparks fear, suggesting possible media coverage or concerns, thus aligning both answers with the media-related context.
**Answer:** Both answers match because the context involves a newsroom, indicating media-related concerns over a casino mogul's intentions.Conclusion
The power of reasoning gives us invaluable insight into the model's functioning and highlights its strengths and weaknesses. It enhances our understanding of the system and provides us with the pathway to make it better.
Imagine a model that only provides the inference decisions without any explanation. Users would never understand why the model is providing these decisions, and it may not inspire much confidence in them.
Hope you liked the content and learned something new today!
Opinions expressed by DZone contributors are their own.
Comments