Optimizing Natural Language Queries for Multi-Service Information Retrieval
Learn how to optimize natural language queries for orchestrated information retrieval across multiple services using AI, GraphQL, and embedding models.
Join the DZone community and get the full member experience.
Join For FreeIn the age of rapid evolution of AI-related technologies, channel applications, e.g., web, kiosk, IVR, etc., are becoming increasingly intelligent where industries are developing strategies to scale the initial experimentations to scaled implementation resolving data quality, governance, and responsible AI challenges. Nonetheless, there is continuous effort put into moving past these inhibitors and scaling the implementations.
Let’s take an example of a channel application that supports foundation customer services. In the traditional architectural approach, the application would consume several APIs exposed by the enterprise with different types, e.g., experience and process APIs, to render the services. More often, in an orchestrated information fetch, this approach has resulted in significant chattiness, network overheads, and performance (e.g., response time) issues.
Also, it accompanied information over fetch than required for the response. Then, GraphQL APIs were introduced to solve many of these problems with the traditional REST API approach. However, as channel applications e.g., web, kiosk, IVR etc are becoming increasingly intelligent, it necessitates a paradigm shift from the traditional design approach to couple the API exposed (GraphQL or REST) from the consumers that provide a natural language interface (the language that end user of the application understand and use) and provide the query or question leveraging that interface.
What would be paramount here is if there is an architectural approach that can leverage this natural language interface while still using the capabilities of GraphQL for a complex and orchestrated information service. The attempt here is to describe such an architectural approach that leverages the Natural Language Interface, AI and GenAI, Industry Information Model, and GraphQL APIs.
Example Use Case Scenario
Let’s take the example of a bank customer asking a question to a channel application, e.g., IVR, web, or kiosk: “Can you help provide a summary of my portfolio (with multiple accounts, e.g., savings, current, term deposits, etc.)?” The input is derived from the registered phone number form where the customer calls, user login, or any other authentication/authorization tokens that lead to the customer reference ID/number as the final input.
For the demonstration, the banking industry is considered, but the approach can be adopted for other industries, e.g., Telco, Travel, Energy, and utility, as there are Industry Information Models available for these industries, such as the Common Information Model (CIM) for Energy and utility, the TM Forum for Telco, etc. BIAN (Banking Industry Architecture Network) prescribes the industry information model for Banking.
Architecture Overview
The diagram below depicts the high-level architecture, components, and steps for realizing the use-case scenario as introduced above.
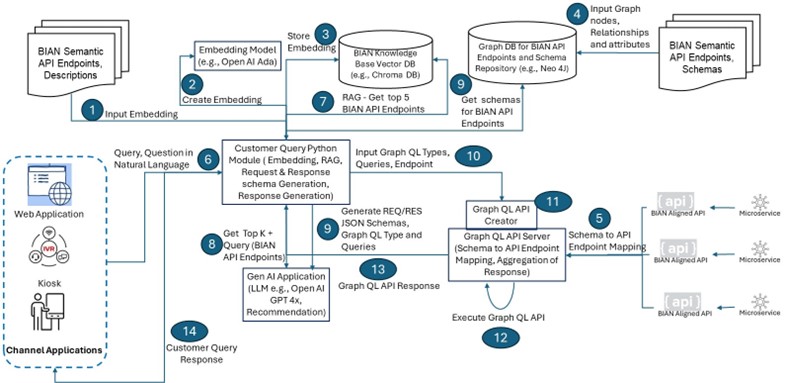
The following section describes the architecture components and steps.
Key Architectural Components/Steps
1. BIAN Semantic API Endpoints and Description
BIAN provides semantic APIs and API endpoints for the capability components, aka service domains, it defines with a set of service operations and business object models or information schemas. It is fair to consider that BIAN leverages Domain-Driven Design to define these service domains and further prescribes these service domains as bounded context to define and develop the microservices with semantic API specification as specified by BIAN.
Refer to the BIAN Semantic API portal for a list of all service domains for which BIAN has defined the semantic API specifications. For this use case scenario, some of the example API endpoints and their descriptions will be as follows.
- https://app.swaggerhub.com/apis/BIAN-3/SavingsAccount/12.0.0
- Endpoint: /SavingsAccount/{savingsaccountId}/Retrieve:
- Operation: get:
- Operation description: ReCR Retrieve information about a savings account - either standard canned reports or selected instance attribute values
- https://app.swaggerhub.com/apis/BIAN-3/CurrentAccount/12.0.0
- Endpoint: /CurrentAccount/{currentaccountid}/Retrieve:
- Operation: get:
- Operation description: ReCR Retrieve information about a current account - either standard canned reports or selected instance attribute values
- https://app.swaggerhub.com/apis/BIAN-3/TermDeposit/12.0.0
- Endpoint: /TermDeposit/{termdepositId}/Retrieve:
- Operation: get:
- Operation description: ReCR Retrieve information about a term deposit account - either standard canned reports or selected instance attribute values
The customer query Python application collates this knowledge base of all BIAN semantic APIs, API endpoints, operations, and descriptions to create embedding.
2. Embedding Model
The customer query Python application creates embeddings for the BIAN semantic APIs, API endpoints, operations, and descriptions collated in the previous step. It can use advanced embedding models that can support structured and unstructured texts, as the API endpoints may contain special characters like “/” and shorter forms of terms without spaces. Some embedding model supports the unstructured texts and help in similarity match better, e.g., Open AI Ada embedding model.
3. Vector Database
The customer query Python application uses a vector database, e.g., Chroma DB, to store these embeddings. The vector database supports the query against a natural language text or description based on various supported text similarity algorithms, e.g., cosine similarity and Euclidean distance.
4. Graph Database
Graph databases store nodes and relationship information models with deep hierarchical trees efficiently and provide query capabilities that can traverse the graph very fast to retrieve information related to nodes and relationships that can span multiple nodes with filter criteria.
For example, Graph DB is Neo4j. Graph databases use Cypher query language to query data, similar to relational databases using Structured Query Language (SQL). Cypher query can support very complex information retrievals from Graph DB, along with support for defining procedures for complex query logic.
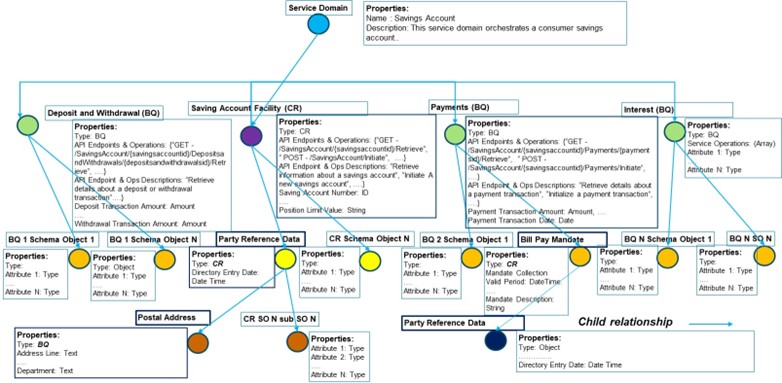
Also, an additional capability of Cypher and Graph DB is the return of the query results in JSON format. As BIAN is a hierarchical Business Object (BoM) schema-based information model with multiple service domains (corresponding semantic APIs, API endpoints, and schemas in JSON objects), Graph DB is a better choice to store this kind of information model and its query capabilities. Graph DB, like Neo4j, also supports graph nodes and relationships to be imported through JSON templates.
Here is an example of how semantic API endpoints, operations, descriptions, and schemas of the BIAN Service Domain Savings Account are represented in Graph DB.
5. GraphQL API Server and GraphQL API Creator
It is assumed that the Bank has adopted Domain-Driven Design and the BIAN Information model to implement the BIAN Semantic APIs through microservices. GraphQL API servers have configured the mapping of response JSON schemas for all the BIAN-compliant actual API endpoints exposed by the Bank’s API Gateways.
These schemas are available as queries and operations on the GraphQL API servers. GraphQL API Creator is a component that automates the GraphQL API endpoint, query, and response generation in the GraphQL API server, largely leveraging GraphQL CLI and auto-generating GraphQL config based on the input request and response JSON schema. It also implements the aggregation of responses from individual data sources or endpoints for the final response object of the GraphQL API Query.
6. Customer Query Python Application
This application is at the heart of the architecture that orchestrates the implementation of the architecture. It implements the following capabilities:
- Creates embeddings for BIAN Semantic API endpoints, operations, and descriptions
- Pushes the embeddings to be stored in Vector DB
- Uses RAG (retrieval-augmented generation) pattern by retrieving the top matches of the embeddings from user natural language query text to BIAN embeddings
- Retrieves the BIAN semantic API endpoints, operations from vector DB, and corresponding schema objects from Graph DB
- Create the request and response schema as required for the user query.
- Invokes the Graph QL API creator component to dynamically generate the GraphQL config and API implementation and invoke the resultant Graph QL API
- Returns the API response to the channel application
7. RAG by Customer Query Python Application for Top N Matches
For the customer query in natural language “Can you help providing a summary of my portfolio (with multiple accounts e.g., savings, current, term deposits etc.)”, Python Application invokes a RAG query to Vector DB for the top matches and the Vector DB is able to retrieve the following BIAN Semantic API endpoint operations as follows:
Endpoint: /SavingsAccount/{savingsaccountId}/Retrieve:
- Operation: get:
Endpoint: /SavingsAccount/Initiate:
- Operation: post:
Endpoint: /CurrentAccount/{currentaccountid}/Retrieve:
- Operation: get:
Endpoint: /CurrentAccount/Initiate:
- Operation: post:
Endpoint: /TermDeposit/{termdepositId}/Retrieve:
- Operation: get:
Endpoint: /TermDeposit/Initiate:
- Operation: post:
8. Top K Recommendations From RAG Results Through LLM
The Python application invokes a large language model (LLM, fine-tuned for industry models like BIAN) with the grounded results from RAG and the customer’s query and asks for the top K (e.g., three matches). Examples of LLM in these cases are Open AI GPT 4.x, Liama 3.x (open source), the IBM foundation model for BIAN (Granite), etc. The LLM returns the top three matches as follows:
Endpoint: /SavingsAccount/{savingsaccountId}/Retrieve:
- Operation: get:
Endpoint: /CurrentAccount/{currentaccountid}/Retrieve:
- Operation: get:
Endpoint: /TermDeposit/{termdepositId}/Retrieve:
- Operation: get:
9. Schemas of API Endpoint Operations From Graph DB
The Python application queries the Graph DB using Cypher query to get the schema (JSON formatted) for the API endpoint operations recommended by the LLM in the previous step. The Graph DB. Example Cypher procedure used is as follows:
Example Cypher query:
MATCH p=(n: CR)-[:needs*]->(m)
WHERE NOT ()-[:needs]->(n) and n:API Endpoints & Operations = “GET - /SavingsAccount/{savingsaccountid}/Retrieve”
WITH COLLECT(p) AS ps
CALL apoc.convert.toTree(ps) yield value
WITH value
RETURN apoc.convert.toJson( value
) as jsonOutput
Example query result will look like:
{
.....
CustomerReference involvedparty{...}
....
AccountCurrency accountcurrency{...}
....
AccountNumber account{...}
..
PositionLimitValue value{...}
…}If the other API Endpoint operation values are added to the Cypher query, it will return the schema objects for the Current Account and Term Deposit as well.
10. Generate REQ/RES JSON, Graph QL Types, Query, and API Endpoints Leveraging LLM
The Python module can again leverage the LLM to generate the optimized request response schemas for the Customer query in natural language, and the schemas returned in the previous step are provided as context. The generated request and response schemas may look like as follows:
REQUEST:
{
"customer": {
"party_referenc_id": "XX234678"
}
}
RESPONSE:
{
"customer": {
"party_referenc_id": "XX234678",
"SavingsAccountFacility": {
"SavingsAccountNumber": "string",
"AccountCurrency": "string",
"PositionLimitValue": "string"
},
"CurrentAccountFacility": {
"CurrentAccountNumber": "string",
"AccountCurrency": "string",
"PositionLimitValue": "string"
},
"TermDepositFacility": {
"TermDepositAccountNumber": "string",
"AccountCurrency": "string",
"PositionLimitValue": "string"
}
}
}The LLM inspects the Swagger (OpenAPI) definitions and maps them to GraphQL type definitions. Additionally, it constructs GraphQL queries by analyzing endpoints and their parameters defined in the paths section of the Swagger file.
Finally, RAG combines the generated type definitions and queries into a unified GraphQL schema file. This approach can be further optimized by incorporating exception handling, pagination, and caching mechanisms following industry best practices.
11. GraphQL API Creator Generates the GraphQL API Endpoint
Given the REQUEST and RESPONSE schemas generated in the previous step, the Python application invokes the GraphQL API Creator to create the GraphQL API endpoint, generate the Query, operations, config, and response aggregation in the GraphQL API server as required.
API creator induces a change that is required in the GraphQL resolver to integrate with the backend application. A rule template-based approach is recommended to dynamically invoke REST API exposed by SORs from a GraphQL resolver.
The Orchestration rules can be defined in a rule template to orchestrate API calls from GraphQL Subgraph to backend APIs, as mentioned below.
| subgraph | query | backend api | order | cardinality |
|---|---|---|---|---|
|
Account |
getAccount |
getAccounts |
1 |
1 |
|
Account |
getAccount |
getAccountDetails |
2 |
Multiple |
In addition, another rule template with predefined configuration/mapping can be used for dynamic integration with the backend system. This integration rule template will be generated through RAG tuned to work at the organization level.
Rule Template With Core Banking APIs
{
"getAccountDetails": {
"endpoint": "https://api.mystarbank.com/accounts/{accountNumber}",
"method": "GET",
"headers": {
"Authorization": "Bearer {authToken}"
},
"requestMapping": {
"accountNumber": "accountNumber" // GraphQL `accountNumber` maps to REST API `accountNumber`
},
"responseMapping": {
"accountId": "id",
"accountHolderName": "name",
"accountBalance": "balance",
"currency": "currencyCode",
"accountType": "type"
}
},
"getAccounts": {
"endpoint": "https://api.mystarbank.com/users/{userId}/accounts",
"method": "GET",
"headers": {
"Authorization": "Bearer {authToken}"
},
"requestMapping": {
"userId": "userId" // GraphQL `userId` maps to REST API `userId`
},
"responseMapping": {
"accounts": {
"accountId": "id",
"accountHolderName": "name",
"accountBalance": "balance",
"currency": "currencyCode",
"accountType": "type"
}
}
}
}12. GraphQL API Server Executes the GraphQL API Endpoint
Based on the config and REQUEST and RESPONSE schemas, the GraphQL API server inspects the schema mapping to API endpoints that match the required fields. It invokes those API endpoints and retrieves the JSON result objects.
The GraphQL API subgraph inspects the integration rule template to extract the matching mapping schemas and integration API endpoints. Subsequently, it invokes those API endpoints in order defined in Orchestration Rule template, retrieve the JSON result objects, transform and aggregate it and route it back as a single response to the requestor.
The benefit of this approach is
- This approach streamlines API integration by centralizing the mapping rules.
- It enhances GraphQL's functionality by incorporating rule-based orchestration logic.
- Centralized, rule-based mapping fosters reusability across the organization.
- The use of LLM and RAG speeds up the initial creation of the integration rule template.
13. GraphQL API Server Returns Response to the Python Application
The GraphQL API server aggregates the response as per the RESPONSE schema and sends the response. Example response looks as follows:
{
"customer": {
"party_referenc_id": "XX234678",
"SavingsAccountFacility": {
"SavingsAccountNumber": "ABCD1234",
"AccountCurrency": "USD",
"PositionLimitValue": "1256"
},
"CurrentAccountFacility": {
"CurrentAccountNumber": "EFGH7845",
"AccountCurrency": "USD",
"PositionLimitValue": "65724"
},
"TermDepositFacility": {
"TermDepositAccountNumber": "BGHE2142",
"AccountCurrency": "USD",
"PositionLimitValue": "7894"
}
}
}14. Python Application Sends Response to Channel Application
The Python application can optionally convert the response to a human voice or interactive chat format and respond to the respective channel application.
Conclusion
As organizations' customers become technology aware and savvy, customer interaction expectations are increasing, demanding greater experience. Instead of following a standard user guide on channel applications for specific tasks, customers are imagining orchestrated insight through natural language questions. This drives the evolution of flexible and AI-driven solutions rather than traditional fixed API-based architecture.
Opinions expressed by DZone contributors are their own.
Comments