Why Rate Limiting Matters in Istio and How to Implement It
In this post, we’ll explore why rate limiting is important in Istio and show you how to set it up effectively.
Join the DZone community and get the full member experience.
Join For FreeIn today's microservices-driven world, managing traffic smartly is just as crucial as deploying the services themselves. As your system grows, so do the risks — like overuse, misuse, and cascading failures. And if you're running multi-tenant services, it's essential to enforce request limits for each customer. That’s where rate limiting in a service mesh like Istio can make a big difference. In this post, we’ll explore why rate limiting is important in Istio and show you how to set it up effectively.
Why Rate Limiting Matters in Istio
Why Was It Important for Us?
This is in continuation of the incident that we faced, which is detailed in How I Made My Liberty Microservices Load-Resilient. One of the findings during the incident was the missing rate limiting in the Istio ingress private gateway. Here are the challenges that we faced:
- Challenge 1: Backend Overload During High-Traffic Events: Our services — especially user-facing APIs — would get hit hard during high traffic. Without any rate controls in place, back-end services and databases would spike, leading to degraded performance or even downtime.
- Challenge 2: Need for Tenant-Based Throttling: We support multiple customers (tenants). We needed a way to enforce quotas, ensuring one tenant’s overuse wouldn’t impact others.
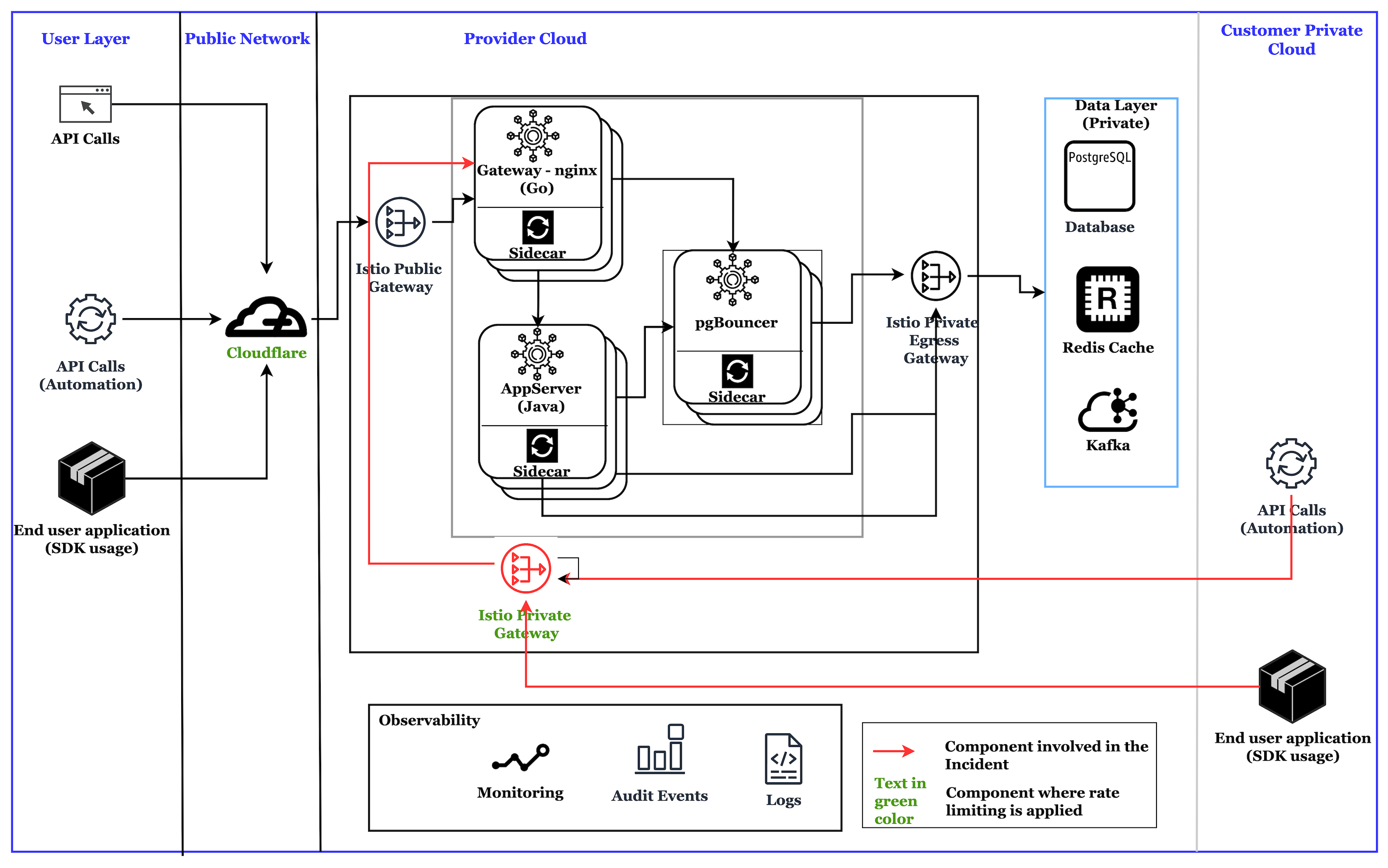
Architecture
Here is a simplified version of the application architecture, highlighting the key components involved in the Istio rate limiting.
Why Rate Limiting Matters in Istio
Rate limiting is a mechanism to control how many requests a service or user can make over a given time interval. In the context of an Istio service mesh, it serves several important purposes:
- Protecting Backend Services: Without rate limiting, a sudden spike in requests — whether from legitimate users or abusive clients — can overload back-end services and databases. Rate limiting helps prevent service degradation or outages.
- Fair Usage and Quotas: Ensures fair access in a multi-tenant system among our tenants by enforcing per-user limits.
- Cost Control: In cloud-native environments, uncontrolled requests can lead to excessive resource usage and unexpected costs. Rate limiting helps contain those costs.
- Security and Abuse Prevention: Blocking excessive requests from abusive users can mitigate denial-of-service (DoS) attacks or brute-force attempts.
- Improved Reliability: By limiting how fast clients can make requests, services stay more responsive and predictable, even under heavy load.
With implementing rate limiting in Istio, there are two places where it is applied. One for the public endpoint customers is done using Cloudflare, and another for private endpoint customers is using Istio.
Local Rate Limiting vs Global Rate Limiting
When implementing rate limiting in an Istio mesh, it’s important to understand the difference between local and global rate limiting, as they serve different use cases and come with distinct trade-offs.
Local rate limiting is enforced individually on each Envoy sidecar proxy. The rate limit is applied at the instance level, meaning each pod or replica gets its own independent limit. Global rate limiting is centrally managed using an external RLS. Envoy sidecars query this central service to decide whether to allow or deny a request, ensuring cluster-wide enforcement.
Note: Local rate limiting in Kubernetes is enforced per pod. This means the token or request count value you configure applies to each individual pod independently.
For example, if you have 5 pods and want to enforce a global limit of 100 requests per 60 seconds, you should configure the local rate limit token value to 20 per pod (i.e., 100 / 5 = 20). This calculation assumes that the load balancer distributes traffic evenly across all pods.
|
Feature |
Local Rate Limiting |
Global Rate Limiting |
|
Enforced At |
Individual Envoy proxy |
Central Rate Limit Service |
|
Scope |
Per pod/instance |
Across all instances |
|
Infrastructure Required |
None |
Redis + Rate Limit Service |
|
Granularity |
Basic (fixed per pod) |
Fine-grained (per-user, route) |
|
Use Case |
Simple protection |
Multi-tenant, API Gateway |
|
Scalability Awareness |
No |
Yes |
Let's explore how to configure Local Rate Limiting in a Kubernetes environment.
Steps to Set Up Local Rate Limiting in Istio
Step 1: Create the EnvoyFilter for Local Rate Limiting
Descriptors are keys used to match requests and apply limits. Example config.yamlfor Envoy:
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: ingress-gateway-ratelimit-envoyfilter
namespace: <namespace>
spec:
configPatches:
- applyTo: HTTP_FILTER
match:
context: GATEWAY
listener:
filterChain:
filter:
name: envoy.filters.network.http_connection_manager
patch:
operation: INSERT_FIRST
value:
name: envoy.filters.http.local_ratelimit
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: >-
type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
- applyTo: VIRTUAL_HOST
match:
context: GATEWAY
routeConfiguration:
gateway: <namespace>/<gateway-name>
portName: https-custom-regional
portNumber: 443
patch:
operation: MERGE
value:
rate_limits:
- actions:
- request_headers:
descriptor_key: method
header_name: ":method"
typed_per_filter_config:
envoy.filters.http.local_ratelimit:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: >-
type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
always_consume_default_token_bucket: false
descriptors:
- entries:
- key: method
value: "GET"
token_bucket:
fill_interval: 60s
max_tokens: 10
tokens_per_fill: 10
- entries:
- key: method
value: "POST"
token_bucket:
fill_interval: 60s
max_tokens: 2
tokens_per_fill: 2
- entries:
- key: method
value: "PATCH"
token_bucket:
fill_interval: 60s
max_tokens: 4
tokens_per_fill: 4
filter_enabled:
default_value:
denominator: HUNDRED
numerator: 100
runtime_key: local_rate_limit_enabled
filter_enforced:
default_value:
denominator: HUNDRED
numerator: 100
runtime_key: local_rate_limit_enforced
response_headers_to_add:
- append: false
header:
key: x-local-rate-limit
value: 'true'
- append: false
header:
key: retry-after
value: '60'
stat_prefix: http_local_rate_limiter
token_bucket:
fill_interval: 60s
max_tokens: 40
tokens_per_fill: 40
workloadSelector:
labels:
<gateway-label>: <gateway-label>Provide the Gateway name and namespace in route_configuration section, as we are applying the rate limiting for Gateway pods. WorkLoadSelector will have the pods labels where you want to apply rate limiting.
The token bucket algorithm is used to define a bucket that holds a limited number of "tokens" representing allowed requests. The bucket is continuously refilled with tokens at a specific rate (tokens per second or minute). When a request arrives, it consumes a token from the bucket. If the bucket is empty, subsequent requests are rejected (rate-limited) until the bucket refills.
Imagine a bucket with a capacity of 10 tokens, refilled with 1 token every second. If 10 requests arrive within 1 second, they will all be allowed, but the 11th request will be rejected until the bucket refills.
Istio supports both local and global rate limiting. Local rate limiting applies to individual service instances, while global rate limiting applies across all instances of a service. In local rate limiting, each Envoy proxy (representing a service instance) has its own token bucket, and the token bucket quota is not shared among the replicas. In global rate limiting, the token bucket quota is shared among all Envoy proxies, meaning that the service will only accept a certain number of requests in total, regardless of the number of replicas.
In the above configuration, token_bucket is defined in the (HTTP_ROUTE) patch, which includes a typed_per_filter_config for the envoy.filters.http.local_ratelimit local envoy filter for routes to virtual host inbound for https at port 443.
max_tokens specifies the maximum number of tokens in the bucket, representing the maximum allowed requests within a certain time frame. tokens_per_fill indicates the number of tokens added to the bucket with each fill, essentially the rate at which tokens are replenished. fill_interval defines the time interval at which the bucket is replenished with tokens.
In the example above, we configured rate limits for specific HTTP methods like GET, POST, and PATCH. You can add or remove methods in this section based on your requirements. The token values assigned under each method define the rate limit for requests using that method. If a request uses a method that isn't explicitly listed, the default token value (configured below stat_prefix) will apply instead.
Step 1.1: Define Rate Limit per Instance (Optional)
If you need tenant-based rate limiting, enable it based on the instance ID (or any other value as applicable) of the tenant instead of the above configuration mentioned in Step 1. Below is the updated configuration to rate limit based on the instance ID. The instance ID, in our case, is part of the request URL.
So, the below configuration has two noticeable updates:
- Rate-limiting descriptors are added with entries to the instance ID value as a key-value pair. These are the instance IDs, which generally have a heavy load, and these are identified based on the history of requests for rate limits.
- Source code addition: function
envoy_on_requestis added to retrieve the instance ID from the request URL and to match the instance IDs identified in the above one.
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: ingress-gateway-ratelimit-envoyfilter
namespace: <namespace>
spec:
configPatches:
- applyTo: HTTP_FILTER
match:
context: GATEWAY
listener:
filterChain:
filter:
name: envoy.filters.network.http_connection_manager
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.local_ratelimit
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: >-
type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
- applyTo: VIRTUAL_HOST
match:
context: GATEWAY
routeConfiguration:
gateway: <namespace>/<gateway-name>
portName: https-custom-regional
portNumber: 443
patch:
operation: MERGE
value:
rate_limits:
- actions:
- request_headers:
descriptor_key: rate-limit
header_name: x-instance-id
typed_per_filter_config:
envoy.filters.http.local_ratelimit:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: >-
type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
always_consume_default_token_bucket: false
descriptors:
- entries:
- key: rate-limit
value: ```"<instance-id>"```
token_bucket:
fill_interval: 60s
max_tokens: 2
tokens_per_fill: 2
- entries:
- key: rate-limit
value: ```"<instance-id-2>"```
token_bucket:
fill_interval: 60s
max_tokens: 5
tokens_per_fill: 5
filter_enabled:
default_value:
denominator: HUNDRED
numerator: 100
runtime_key: local_rate_limit_enabled
filter_enforced:
default_value:
denominator: HUNDRED
numerator: 100
runtime_key: local_rate_limit_enforced
response_headers_to_add:
- append: false
header:
key: x-local-rate-limit
value: 'true'
- append: false
header:
key: retry-after
value: '60'
stat_prefix: http_local_rate_limiter
token_bucket:
fill_interval: 60s
max_tokens: 40
tokens_per_fill: 40
- applyTo: HTTP_FILTER
match:
context: GATEWAY
listener:
filterChain:
filter:
name: envoy.filters.network.http_connection_manager
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.lua
typed_config:
'@type': type.googleapis.com/envoy.extensions.filters.http.lua.v3.Lua
default_source_code:
inline_string: |
function envoy_on_request(request_handle)
local path = request_handle:headers():get(":path") or "nil"
request_handle:logInfo("Request received: " .. path)
local instance_id = path:match("/instances/([^/]+)/")
local rate_limited_instance = ```"<instance-id>"```
local rate_limited_instance_2 = ```"<instance-id-2>"```
local method = request_handle:headers():get(":method")
if instance_id then
request_handle:logInfo("Extracted Instance ID: " .. instance_id)
else
request_handle:logInfo("No Instance ID found in path")
end
if instance_id == rate_limited_instance or instance_id == rate_limited_instance_2 then
request_handle:logInfo("method: "..request_handle:headers():get(":method"))
if method == "GET" then
request_handle:logInfo("Applying rate limiting for instance_id: " .. instance_id)
request_handle:headers():add("x-instance-id", tostring(instance_id))
request_handle:logInfo("instance_header: "..request_handle:headers():get("x-instance-id"))
else
request_handle:logInfo("Not get call for instance_id: " .. tostring(instance_id))
end
else
request_handle:logInfo("No rate limiting for instance_id: " .. tostring(instance_id))
end
end
workloadSelector:
labels:
<gaterway-label>: <gaterway-label>Note: Since we used a custom Envoyfilter, we need not deploy Redis, which is otherwise used for metadata like counters and TTLs.
Step 2: Test the Configuration
Send requests to your service and observe if the rate limits are triggered. You can check the logs from the pods where you have applied rate limiting.
Step 3: Monitor the Requests That Are Rate Limited
Today, we monitor the rate limits from logs. But in the future, we would enable Prometheus/Grafana dashboards to observe the rate-limited traffic.
Conclusion
Rate limiting in Istio is not just a performance enhancement — it’s a strategic traffic control mechanism that protects your services, ensures fairness, and supports system scalability. Whether you're securing an API gateway or managing internal service communication, rate limiting should be part of your Istio playbook.
Opinions expressed by DZone contributors are their own.
Comments